Last week we got news of the Rosebutt data breach. This is a very particular class of site and like many others we've recently seen compromised, it's highly likely that members would have preferred to keep their identities secret. It doesn't matter if you don't agree with the lifestyle choice of those on the site and certainly I myself am not one to look around the house at everyday items and think "I wonder if that could...". That's entirely beside the point though which is that a bunch of consenting adults now have their identities in the hands of an untold number of people who are willingly sharing the data around web. But it didn't have to be that way.
I've had this post in mind for some time as I've seen more and more deeply personal data spread across the web. Ashley Madison is a perfect example of that and many people were shocked at just how many real identities were contained in the data, identities that then caused a great deal of grief for their owners.
I want to talk about practical, everyday things that people who aren't deeply technical can do to better protect themselves. They're simple, mostly free and easily obtainable by everyone. I'd also like to encourage those who do give online anonymity a lot of thought to leave their suggestions in the comments section, keeping in mind the target audience being your normal, everyday people.
Let's start somewhere extremely practical yet often not acknowledged in discussions on privacy and anonymity.
Who are you hiding your identity from?
This is a fundamentally important questions because it greatly impacts the defences you apply. The measures you take to hide your identity from, say, a significant other or general member of the community may not be sufficient to hide from government oversight. Of course the latter will usually also protect you from the former, but it also often comes with an additional burden to implement.
I'm going to focus on what's readily accessible to the bulk of the population. If you don't want your participation in certain sites going public, then this will be useful. If you're a budding Edward Snowden then you'll need to go much, much further.
Let's jump into it, and we'll start somewhere simple.
Don't use your real email address
The easiest personal identifier that will match you to a site is your email address. It's a well-known identity attribute, it's unique to you and there are multiple ways of discovering if it exists on a given website. One of those ways is obviously when data is breached from a system and all the email addresses are on easy display:
Curious how newsworthy .gov addresses are: "Australian government workers exposed as hackers attack dating site": https://t.co/OhHyFvzDGH
— Troy Hunt (@troyhunt) April 26, 2016
But another way is via an enumeration risk. For example, you can go to the Adult Friend Finder password reset page and you simply enter an address - any address. The page will then tell you if it exists or not. It's not always that explicit either, for example Ashley Madison returned slightly different responses which could still be observed.
Don't use your personal email address. Don't use your work email address. Go to gmail.com and fabricate one. When you do fabricate one, don't put your real name in it! You can fat-finger the keyboard or enter a fabricated name but don't use your own. Also consider how you fill out the following form when you create the account:
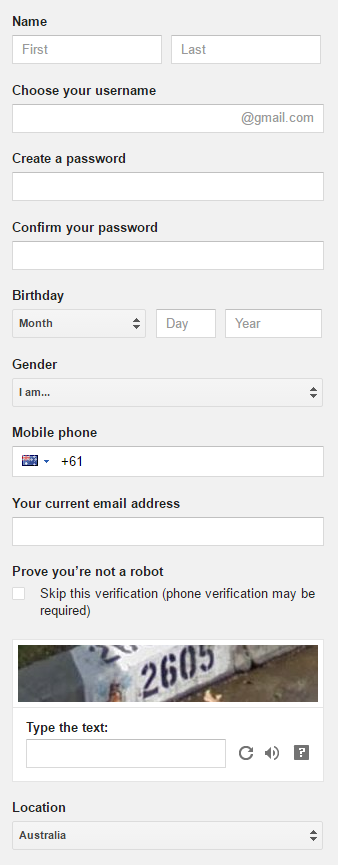
These attributes won't show up on other sites where the address is used, but they can start to surface in other places. For example, when doing a password reset:

If you authenticate to another site using your Gmail account (social logins are increasingly common), then you may be prompted to share data attributes such as your name with that site. When you create a set of personally identifiable attributes such as those in the Gmail signup screen above, there are all sorts of ways that info can be leaked. Not just the mechanisms above, there's always legal requests by law enforcement. Whilst that's unlikely to be the threat that most folks just wanting to remain genuinely anonymous on the classes of personal site we continually see being breached, it's also an unnecessary risk.
Gmail (or equivalent - there are many other free online mail providers) gives you a full blown email address and obviously requests a lot of info in the process. A great alternative where an email address is simply a requirement to entry and you care little about anything that's actually sent to it is to use a Mailinator address. For example, you can enter an address such as foo@mailinator.com then head off to Mailinator, enter the alias and immediately view the contents of the mailbox:

There's no authentication and therefore you need to assume there's no confidentiality (although the likelihood of someone stumbling across a genuinely randomised email alias is extremely low), but when email is simply a barrier to site entry then Mailinator is a very simple solution. Many of the data breaches I come across have numerous Mailinator addresses in them for precisely this reason.
The email address is the first, most logical step and honestly this is a huge portion of the anonymity story as it relates to identities being spread around the web when a system is compromised. But we can go further than that, much further.
Crafting an identity
Consider the data that many sites request on signup: name, location (possibly your exact address), date of birth, phone number etc. If protecting your identity is indeed important to you, consider what these values should be. If there's never any adverse recourse from fabricating them then do just that - make them all up. Make sure you record them though as they may be required for identification purposes later on, for example your date of birth is requested as part of an account unlock process. Don't put them in a text file on your desktop called "my secret online identity", put them in an encrypted keychain such as 1Password's.
Not the creative type? Then go generate yourself a fake identity:
Be conscious also that sometimes the phone number is required for verification purposes, for example you may need to demonstrate that you can receive and SMS to the number. There are services available that allow you to receive an SMS to a number other than your own so that can help protect your actual number. Alternatively, go out and buy a cheap SIM that's enough to receive an SMS on. Some countries require you to verify your identity in order to do this, but if you're simply protecting your identity from the broader community then that's not a problem, it's not a number that will be publicly linked to you. Remember, that's just as uniquely identifying as an email address so it's not a data attribute you want to be sharing.
Making payments
Often people's fabricated personas come undone once payments are involved. For example, in the Ashley Madison data breach there was a very large number of payment records that logged personal attributes uniquely identifying the member, even after that member had paid for the "full delete" service. Due to the nature of many forms of online payment and the obvious potential for fraud, sites like Ashley Madison like holding onto as much data as they can so financial transactions can have a pretty long paper trail.
One option for getting away from using your everyday credit card for purchases is to get a virtual card, for example via the likes of Entropay. It's quick to setup and it operates like a debit card. You need to put cash on it but then as far as the merchant you're paying is concerned, there's no traceable route back to the original card. Of course there's a name on the card, but that may come from the fabricated identity earlier on (the issue of how that sits with Entropay's T&Cs aside).
There are other virtual credit cards that act like a debit card and simply require a top up before they can be used, the point is simply that there exists a paradigm that allows payments in this fashion.
Then there's good old crypto currency which is a favourite among those wanting to obfuscate their identity. Thing is though, as much as I love Bitcoin (try using it for perfectly legitimate, above board purposes one day just to experience it), the mainstream, above board places you can use it are pretty limited. For example, here are your options to pay Ashley Madison money:

The virtual credit card approach would work, as would a PayPal account. Of course paying with PayPal sends the identity of the payer so whilst they request a full legal name at signup, in theory, you could sign up with something else. Hypothetically, of course. You may then be happy linking a real card or bank account or paying to it from another PayPal account as that identity doesn't get passed on downstream when purchases are made.
Obviously I've (not particularly subtly) skirted around the topic of using fake details to sign up to financial services and this may or may not bother some people (probably much more "not" if they're trying to hide their identity anyway). Just be conscious that when you use fake information with a service - particularly one that manages money - you may well find the account suspended at some time and it could be tricky to recover. Proceed with caution.
Browsing anonymously
In terms of your exposure to a particular site you may not wish to make public, have a look at how many data breaches I've loaded into Have I been pwned (HIBP) that include IP addresses. Many forum products capture and store them by default and many sites use them to identify everything from a rough physical location to possible fraudulent activity.
These sites are storing your publicly facing IP address, that is the address they see when you make requests to their sites. If you're at home, all your machines within your home network have the same outbound address. The same often (but not always) applies to requests from within corporate networks. Particularly in the home though, there's a very high chance of the IP address uniquely identifying you. For example, your significant other jumps on the home PC and heads to whatismyip.com which tells them something like this:

Find that IP address in, say, the Adult Friend Finder data breach and there's going to be some explaining to do. Not always, mind you; whilst many people have "static" IP addresses (the one IP sticks with them for the life of their time with the ISP), many others are dynamic (the ISP rotates the addresses over time). In fact, where an IP address is dynamic, someone may be unfairly implicated simply because they obtain an address previously used by someone else. Of course ISPs have logs of which addresses they provisioned to which customers (indeed these are often requested by law enforcement), but that doesn't solve the "suspicious partner" problem.
There are several options to hide your identity and we'll start with one that doesn't work in the way many people think it does:
Incognito mode in Chrome or private browsing in Firefox and Internet Explorer or more colloquially, "porn mode", have their uses, but what they won't do is hide your IP address from the sites you're browsing. What they're useful for though is giving you a "clean" browser session, that is one without cookies, cached files and browser history such that when you browse around the web, it's like being on a totally clean machine.
Incognito works best in conjunction with a VPN and indeed that's what I snapped the earlier screen cap of my IP address whilst using. A VPN gives you an encrypted tunnel between your machine and the VPN exit node. In the case above, I chose to go out via F-Secure's Singapore node using their Freedome VPN product. What this means is that any site looking at my IP sees F-Secure's, not mine. F-Secure see mine and were they so inclined, they could observe that it was my source IP actually browsing the site and indeed this means you put an enormous amount of trust in the VPN provider. I chose them precisely because of that - I trust them - and whilst the price point is higher than some of the others (although we're still only talking €4 a month for up to 3 devices), trust is paramount. Here's what I'm seeing as I write this:

The primary value proposition of a VPN for me is that it means I can use public wifi while travelling and not worry about my traffic being intercepted by an airport or the hotel. But it also hides my source IP address and once combined with Incognito mode means that not only is my address hidden, the sites I've previously visited are too. Just using a VPN and a normal browser window puts you at risk of cookies in the browser associating your true identity to your browsing habits. For example, Facebook has tentacles in just about everything; visiting a site that integrates, say, the Facebook "like" button while you're logged into Facebook with that browser will announce your movements to them. Furthermore, accidentally hit a like button and now you're announcing your browsing habits to your friends.
Another option that's totally free is to use Tor. Traditionally thought of as "The Dark Web", Tor allows sites to run in a fashion that makes it difficult to identify where they actually are but it also enables people to browse the "clear web" anonymously. The Tor browser bundle can easily be installed on Windows, Mac or Linux and is a pretty familiar experience:

The difference to browsing with, say, Chrome on the desktop though is that your traffic is routed through multiple nodes along the way such that your source IP address is not presented to the site you're browsing. This now puts us somewhere altogether different:

Furthermore, it's easy to take a new identity within the Tor browser and jump out through another exit node and consequently obtain a new IP address. But there are problems with this approach too; for one, you're entrusting your traffic to some unknown party running an exit node. Traffic sent over HTTP (not HTTPS) can be observed and manipulated via someone running a malicious exit node. You'll also run into trouble with many sites treating Tor traffic as suspicious. CloudFlare recently wrote that 94% of the traffic they see from Tor is Malicious and consequently they continually pop up a CAPTCHA by default (this blog routes through CloudFlare but I've disabled that "feature" for Tor traffic). Even just loading that IP address checking site above resulted in me having to answer multiple CAPTCHAs and it's not a pleasant browsing experience.
None of these approaches are foolproof and all of them carry some burden of overhead with them, but for "normal people" (that is not techies or those worried about government interception), a good VPN and Incognito mode goes a very long way to protecting your identity. Just don't forget to enable the VPN before browsing!
Summary
For the purposes of protecting yourself from incidents such as I opened this blog with, most people are simply looking for one degree of separation from the site. This means that they don't want to give the site anything personally identifiable, but they may be happy to give other services upstream of there certain info. Think about this carefully when you create accounts; who are you giving personally identifiable data attributes to and where might they be passed on to?
I'm also conscious that the guidance here could be used to hide identities on sites that most reasonable people would not like to see others participating in. The advice above is not going to entirely circumvent law enforcement - it's not supposed to - it's simply there to enable you to participate in communities where anonymity is important. Start throwing in police surveillance, court orders and data requests of service providers and the wheels will fall off very quickly.
Online privacy is not necessarily about having something to hide, it's often about simply not wanting to share certain activities. If you consider that everything you do on the web might one day become public, you may well find there are classes of site you use where privacy is actually rather important.