![It's a new blog!]()
It's been 434 blog posts over six and a half years. It's gone from being excited about a hundred visitors in a week to hundreds of thousands on a big day. It's taken me from a hobby to a career. In so many ways, this blog has defined who I am and what I do today but finally, it was time for a change.
You're now reading an all new blog in an all new design on an all new platform. The content is the only thing that remains and I've literally rebuilt everything from the ground up over the last few months. Over that time, I've made many promises to explain how I decided to do it so my first post on the new platform is going to be a very meta-post about how everything you're seeing here has been put together. I'd love to get your feedback too so please do use the comments below; tell me what you love or hate or think I can improve and whilst I may not be able to do everything, I can at least read all feedback and I'm sure a bunch of it will lead to positive improvements.
Ghost, Ghost Pro
Last year I had to create a new blog. Not for me, mind you, rather for my wife, Kylie. I wanted something she could self-manage and that was a good, modern day platform. I looked at WordPress options but there were a number of things that just didn't sit well with me on that front. One of them was the sheer scale of security issues they have and before you interject, yes, I know that's usually because of third party add-ons yet the ecosystem still facilitates this. Then there was just the multitude of things that WordPress sites do that she simply didn't need - all she wanted was a blog, not add-ons and forms and other things that were ancillary to the simple objective of just creating a blog.
You can read more about it in Creating a blog for your non-techie significant other; the path to Ghost but as the title suggests, the solution was ultimately to move her to Ghost. And then I got a bit jealous because her site looked so damn good! It doesn't just look good, it's all HTTPS, loads super-fast and is a joy to work with.
After creating Kylie's blog and writing about the process, I began having a bit of dialogue with John O'Nolan from Ghost, AKA the guy who created Ghost. I was already keen to move this blog for a whole bunch of reasons that will become clear as you read this post, and John offered to help make it happen. It was never going to be a simple task and particularly as an independent these days, I have to think carefully about where I spend my time. The offer of support was enough to tip me over into saying "yes" and now here we are!
One more thing before I get into the details; this blog is running on Ghost Pro which is their commercially hosted version of the otherwise free Ghost blogging platform. A lot of people have suggested I should host it myself on Azure or Digital Ocean or similar and I have absolutely zero interest in doing that for a blog. Let me explain.
Hosting websites is like having kids; they're continually attacked by nasty things, they need ongoing care and as good an idea as they may seem at the time, they end up costing you a heap more than you planned. And no, I don't care that [whatever your favourite is] only costs 3 cents a month because that's not what matters; time is the commodity that's most valuable to me now. It's not just time in terms of hours actually spent, it's needing to be ready to patch any nasties, managing (and testing) backups, installing updates so you can leverage new features and so on and so forth. Let's be overly optimistic about it and say all that only takes 2 hours a month - what's that worth to you? Go on, put a dollar figure on it and consider what you could charge for the time plus what it's worth to simply not have to think about it.
Alternatively, check out this one the Ghost folks prepared earlier which I wholeheartedly agree with:
![It's a new blog!]()
You do have to make trade-offs on a managed platform like Ghost Pro. For example, I can't add custom responses headers and implement a content security policy. On the other hand, I'm not patching it and securing the environment as I would be if I managed it myself which would give me access to headers so I'm effectively trading off one security defence of limited value to a read-only personal blog and substituting it with a far more valuable defence which is letting the Ghost pros manage their platform. Pragmatism, people.
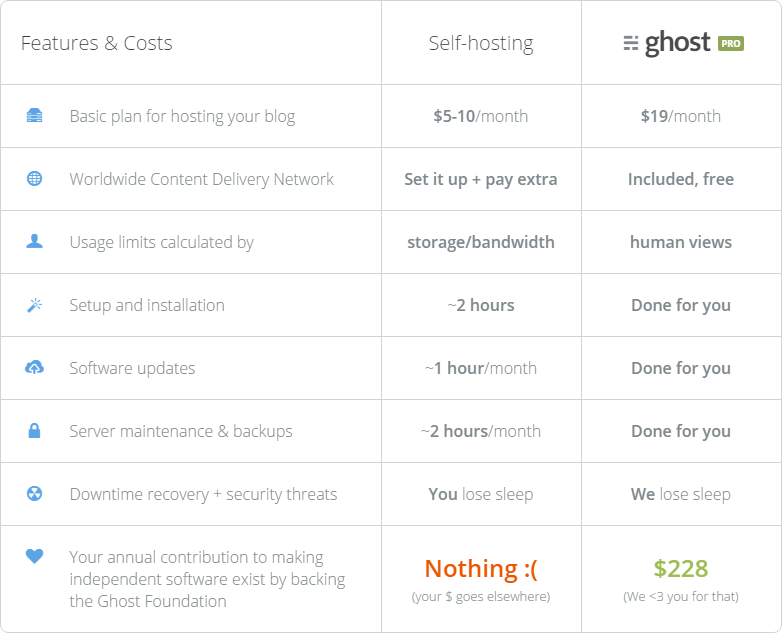
Ghost Pro starts at $19/m and if this seems like an insurmountably high amount, it might be time to think about whether it's worth doing at all if it's not worth ~60 cents a day. That cost can go up if you've got larger traffic numbers, but I'll talk shortly about how to keep that down with CloudFlare as well. For me, it was never up for discussion, a SaaS offering like Ghost Pro is an absolute no-brainer.
Right, that's clear, let me move on to the mechanics of how it's all put together.
CloudFlare
There are three things you need to understand about CloudFlare if you're not already familiar with what they do:
- Their service routes your traffic through their global infrastructure
- They give you security bits and performance bit for free
- It only takes 5 minutes to setup
I wrote about CloudFlare last year and it's a really neat way of simply wrapping services around your existing site. In fact, I was so impressed with CloudFlare that I ended up writing a Pluralsight course on it, Getting Started with CloudFlare Security. At the time of writing the course just under a year ago, they were putting 5 trillion (yes, with a "t") requests a month through their infrastructure, a globally distributed collection of edge nodes that sit, well, pretty much everywhere:
![It's a new blog!]()
When you have a service like this that sits in between customers and the origin website (the one running on Ghost), you can do all sorts of neat performance and security things. Actually let's get onto that now - security - and I'm really happy with this next bit...
It's all HTTPS
I've been hammered by people on my lack of HTTPS for some time, even occasionally being called hypocritical for not having it when writing about the importance of it on other sites. Let me take issue with that for a moment: criticising a commercial website accepting credentials in the clear or a payment provider loading credit card forms insecurely is a world apart from a public blog where you only read information being loaded over HTTP. Absolutist views like this are unhealthy; pragmatism about what security defences make sense in what scenarios is really important.
That said, I really dislike this sort of thing:
I saw it myself last year whilst flying Norwegian and whilst I'm sure this looked great on the marketing slides, it's a profoundly obtrusive and irresponsible thing for them to do. And now they can't because the data is encrypted from your device as it flows out through the network so Norwegian, screw you!
But increasingly, there are other reasons to go all HTTPS on a blog like this one. One is that Google now use it as a ranking signal or in other words, your searchability gets a bump simply by virtue of serving it securely. It's allegedly a minor bump but in a space where SEO techniques are not just very competitive but often very shady, a bump for doing something positive is a very good thing indeed.
Another reason is that sooner or later, sites that aren't served over HTTPS are going to be explicitly flagged as insecure. Think about how it works at present; let's take a site like, oh I dunno, Norwegian airlines:
![It's a new blog!]()
This site is insecure but the browser doesn't tell you that, rather it just loads it up without any visual warning indicators - it's implicitly insecure. Compare that to what you now see in the address bar of this site - green and padlock, depending on your browser - it's explicitly secure. Scott Helme talks about this in his excellent post about Still think you don't need HTTPS? which is well worth a read if you're on the fence about how important the shift to "secure by default is".
You can actually see what this looks like right now: in Chrome, jump on over to chrome://flags/#mark-non-secure-as and tell it to mark non-secure origins as non-secure:
![It's a new blog!]()
Now you head on over to Norwegian airlines and, well:
![It's a new blog!]()
Fortunately, the web as a whole is moving in the right direction albeit at a gradual pace. For example, only a couple of weeks ago Wordpress announced that all sites on wordpress.com would get HTTPS. It's an incremental process that will take many years to filter out to masses of HTTP sites out there but eventually, insecure sites will be the exception so best start moving away from that early.
I've also enabled HSTS which means that once you do see the site over a secure connection, supporting browsers (which is all the major modern ones now), won't load the content over HTTP. I can't force it on subdomains though because I have the likes of hackyourselffirst.troyhunt.com and a couple of others which I want to keep serving content over HTTP. That also means I can't preload (explained in that HSTS link) but again, it's a personal blog, it's not a class of site that warrants the changes required to enable those extra layers of defence. Go and have a good look at the configuration of haveibeenpwned.com if you'd like to see a utopian security headers approach.
One thing to be clear about with HTTPS on this blog is where it begins and ends using CloudFlare's service. What this new blog means is that I've been able to go from zero encryption anywhere to A+ grade encryption from the browser to CloudFlare (so all the most common attack vectors like rogue wireless providers, dodgy ISPs and modified DNS are all good now) and what they call "full" encryption from CloudFlare to Ghost. This protects against passive eavesdropping on that network segment (i.e. the NSA can't just watch the traffic), but doesn't employ what they call "Full strict" encryption which would also protect against an adversary issuing a fake certificate. To do that, I'd need Ghost Pro to support me loading my own certificate for troyhunt.com into the site there and that's not a feature they presently enable, in fact they expressly direct people to do precisely what I've done here with CloudFlare. I'll write more about this another time but for a personal blog, it's more than ample.
Last thing on HTTPS - before anyone says "Well you really need to preload HSTS and use HPKP to be properly secure" - do a quick reality check. No seriously, it's a freakin' blog and as much as I'd like to think it's important enough for Ahmadinejad to go and own another CA and issue rogue certs so that he can inspect your requests to troyhunt.com, it's not. I spend a lot of my time when teaching security courses these days trying to talk about pragmatism; applying the right security levels to the right assets and knowing when to is both very important and sorely lacking. I'll write more on this lately because some of the absolutist attitudes I've seen recently need a bit of bringing back down to earth.
Tor
This is one thing I didn't want happening:
If you believe their stats, 94% of the traffic from Tor is malicious. If you believe Tor, CloudFlare don't know what they're talking about, or at least they analyse the data in a very selective fashion. Regardless, when you route your traffic through CloudFlare, by default users on Tor will be challenged:
![It's a new blog!]()
This is not a pleasant user experience. I get why they're doing it and regardless of what the figures are, a network designed to anonymise the traffic is going to have a bunch of evil stuff come through it that's probably going to be harder to track than via the clear web. If I was wrapping my own app in CloudFlare and I had serious business going on in it that was unlikely to see legitimate traffic coming from Tor, I'd think differently. But when everything is running on a managed service like Ghost Pro, it's not my problem! (Remember, that's another joy of not hosting your own things - they get to deal with any attacks themselves!)
Anyway, the point is that I want to make things as frictionless as possible and as such, I've followed CloudFlare's guidance on whitelisting Tor traffic. Anyone who chooses to browse via Tor will now be able to do so without a challenge. In fact, that was my decision well before even launching the site and it was like that from the very first requests through CloudFlare.
This pleases me enormously:
And this:
This one too:
And all the other ones :)
This is one of the things I'm proudest of - it's chalk and cheese compared to the old blog. Before, I had both a legacy of Blogger-bloat and quite frankly, my own busy content with too many widgets and other bits integrated into the page.
This time, I wanted to go fast. Real fast. Let me show you the quantitative results and I'll start with a page speed test of the old site from Saturday just before I rolled over, here's a link to the actual test:
![It's a new blog!]()
Now that's still faster than 74% of the sites they've tested so not too bad, but it's also 142 requests at 2.1MB and taking 1.9 seconds. In the grand scheme of websites, it's actually not too bad. But I could do better - much better.
Different test tools will rate sites differently too so I wanted to mix it up a bit. I quite like the way GTmetrix breaks down the data so I ran it through there too. Here's a link to the actual test and the results as follows:
![It's a new blog!]()
This test doesn't load the ads so the requests are way down, but the duration was actually higher at 3.3 seconds. Different tests, different methodologies, the main thing is how the new site compares to the old when using the same tools. Let's give that a go, here's a test of the new site.
![It's a new blog!]()
Let me bask in this for a moment:
- The number of requests are down 87%
- The page size is down 81%
- The load time is down 61%
- It's now faster than 94% of (tested) sites on the web!
Let's try GTmetrix, here's the new one:
![It's a new blog!]()
Again, different perf tests will differ in different ways, the main thing is that everything here shows improvement and it's all green! There are always further tweaks that can be made and I do have a few in mind, for example:
There are issues there related to cache expiry and the very limited number of page rules the free CloudFlare offering gives you, but we're well and truly into the realm of very small improvements now.
Perf tweaks galore
Clearly, I'm really happy with the performance of the site and that's been one of the resounding pieces of feedback since I launched. Let me talk through just some of the things I've done to eke out as much perf as I could.
All the obvious things such as bundling and minimising CSS and JavaScript are there. As part of my Node.js journey (Ghost is all built on Node), I wrangled up a Gulp file to handle it all and it not only does the usual tricks of combining files and stripping unnecessary characters, it also combines media queries. The Gulp file is here if you'd like to take a look and I definitely welcome suggestions on that one.
Obviously sitting behind CloudFlare is an important perf decision as well. It makes the difference between my content sitting only within Ghost Pro's Amsterdam hosting and sitting, well, almost everywhere courtesy of that globally distributed CDN map earlier on. You start to understand just how much difference this makes when you look at the stats in CloudFlare:
![It's a new blog!]()
This is over the last 24 hours at the time of writing, a period where I haven't posted anything new and nothing is going nuts as opposed to traffic norms, yet look at the stats. CloudFlare has served 184k requests (about two thirds of them) from nodes close to the user so it's fast for them, but it's also relieved Ghost Pro of those requests plus about 9.5GB of data. That's on a highly-optimised, super-efficient site too so consider what this would mean for a site with heavy pages serving heaps of requests.
There are endless other little tweaks and optimisations too. For example, all the JavaScript and the IFTTT logo in the footer are inlined in the HTML, they're not external files. They don't need to be because they're so small it's not worth loading up the extra HTTP request for the sake of wearing a few extra bytes on every page load.
If there's other perf opportunities you see when browsing the site then definitely let me know. I'm sure they're out there!
Designing the site
I built the last site template running on Google's Blogger from scratch. All hand-rolled including the responsive design bits and all the pain that goes with cross platform testing. I actually think things are easier these days if you're targeting modern browsers, but I still didn't want to deal with it myself.
I began with a false start - I had someone building me a Ghost template and it just didn't work out. It's not that they were bad, it was just one of those things where it was hard for me to articulate what I wanted and for them to turn that into a site. Each time I almost just went "it's good enough" I stopped... and remembered just how critical this site is to the things I do today. It has to represent me and what I do in a way that I'm 100% happy with and compromising just didn't make sense. We iterated many times but ultimately I reached the conclusion that it just wasn't going to work; I had to build it myself.
To be fair though, I cheated. I looked around the Ghost Marketplace and found the template that was the closest to what I actually wanted. Then I started ripping it to pieces. I optimised it fairly significantly, doing things like throwing out SVGs for the social icons and deferring to Font Awesome instead. I discarded fonts I didn't think I needed. I got rid of extraneous markup. In short, I trimmed it down as far as I dared in order to not just get it light, but get it reflecting the image that I wanted to present. That said, there are still artefacts of the original design in there and I'm sure there's wasted bytes floating around, but it's pretty good now :)
There were plenty of crossroads where I had to make calls on design elements that weren't always easy. For example, I started out with hyperlinks having a bottom border rather than the default underline text decoration. This causes other problems:
The answer is simple - kill the bottom border and lose the aesthetically-more-pleasing space between the letters and the line under them. For a site like this, design fluffiness is not worth performance, usability and maintenance costs. That's a question of degrees, of course, and you're still "paying" the cost of downloading a web font used in the text you're reading plus of course there's some big images in the banners, but it's the presence of these style elements which I felt enabled me the kill fussy little things like the borders instead.
Lastly, obviously these days everything has to play nice on mobile, that's an absolute given. This site has much better spacing and large fonts which especially makes a difference on pocket devices. But as important as those devices are and contrary to popular industry beliefs, the vast majority of my traffic from the last month is still via desktop browsers:
![It's a new blog!]()
Further to that, 28% of all traffic is on browsers running 1,920 pixels on the horizontal so we're talking about high-res devices. I've tried to make it play nice across everything and I hope I've been able to do that.
Content migration and new pages
Migrating over 434 blog posts isn't a simple thing, although it did end up being easier than expected. In part that's because of awesome support from the folks at Ghost (and I do mean awesome - I can't speak highly enough of the assistance they gave me), and in part because we cheated just a little bit. Normally you'd create posts in Ghost using markdown which is exactly what I've done with this post, the first one on the new platform. However, you can also just write plain old HTML into the posts and that's effectively what we did with the old posts - just moved over the HTML.
One thing we had to make sure of though was that there was no external content embedded over HTTP otherwise there'd be mixed content warnings when the new blog loaded the parent page over HTTPS. This mostly meant fixing embedded YouTube video references, but I wouldn't be surprised if we've missed a few other content types. Comments section if you find them!
The paths also changed as Ghost doesn't work to the same convention as the old Blogger platform does plus of course I've now also got HTTPS as the scheme. It meant that a URL like this:
http://www.troyhunt.com/2016/04/lenovo-p50-and-my-dislike-of-high-dpi.html
Now becomes this:
https://www.troyhunt.com/lenovo-p50-and-my-dislike-of-high-dpi/
The Ghost folks stood up a bunch of redirects so each "legacy" URL still works just fine. I also uploaded a map into Disqus to migrate comments although disappointingly, that appears to have been only partially successful. Blog posts like the one above don't have any of the old comments appearing on them although I can still see them in the Disqus portal. Other posts came across just fine and I've got a ticket with them now to hopefully get it sorted, although it's been radio silence since I lodged it more than a day ago. Know anyone at Disqus? Give them a nudge for me because frankly, I'm a bit disappointed right now.
One thing I'm kinda curious about with the 301s is what it'll do to my SEO. Paths have changed and the scheme has changed and indeed this has been one of the hesitations that many people have expressed about moving to HTTPS only - what will it do to their searchability? I honestly don't know, but if I see anything worth sharing once everything has been refreshed in the search engines, I'll write about it.
Onto new content - you'll see some links across the top of the page (or in the menu if your device is small). These days, what I'm doing with speaking and particularly the workshops I run are really important. I hope I've captured the essence of those here, it's information I only had in pieces before and consolidating it in a cohesive fashion is really important, particularly to my new life as an independent.
Ads
I’ve kept the same three ads as I’ve had for some time now, although I’ve attempted to make them a little less intrusive. Making them more visible more of the time would obviously have been to my financial advantage but every time I looked at this, it just didn’t feel right. Not right aesthetically and not right in terms of prioritising someone else’s message over what readers have actually come to the site to read.
It’s also completely ad block friendly, in fact I checked it with the major blockers to make sure the page still rendered cleanly and didn’t make a mess of things. Of course I’d like the revenue that comes from the ads, but I’d like people to have a positive experience when they come to my site even more.
Let me digress on ads for a moment: ad networks - you guys have massively screwed this up. I went to town on bad UX in this very popular post earlier this year and shitty behaviour by ad networks was right up there at the top of the worst offenders. One of the practices that most incensed people was Forbes demanding they disable their ad blocker before viewing their content. That's nuts, right? I mean who would ever do that?! Apparently, about half of you:
The ad thing is a mess and it isn't getting better any time soon. I want it to work well and I want people to see my ads because they do actually contribute quite a bit to my efforts when content does well, but above all, I want your experience to be positive.
I was going to go naked...
No, don't get excited, not that naked, rather naked in the sense of troyhunt.com rather than www.troyhunt.com. Of course either would have still worked as both of them always have, it's merely a question of which one becomes the canonical one with the other one simply redirecting to it.
What originally motivated me to want to do this was nothing more than aesthetics; it's a cleaner look not having the www prefix on the URL when you see it on the page. But what stopped me was entirely practical reasons, starting with this tweet:
That site is well worth a read and it has some very valid technical arguments as to why the www prefix makes sense. The more I thought about it, the more I realised that regardless of the technical reasons, my aesthetic arguments didn't really make sense anyway. For example, here's the site loaded on my iPhone now:
![It's a new blog!]()
And here's how Twitter is showing links:
![It's a new blog!]()
These are both www prefixed sites, the respective apps just auto-strip them off when displaying the URL. Now we're in this realm of decreasing aesthetic value, negative technical impact and a change from the existing status quo. So I left it as is and I reckon that's the right decision.
Search
Gone. Dead. Cactus.
The original reason for the decision it is that there's simply no support for search in Ghost. But on further reflection, I began to wonder how much it was actually used and the Google Analytics stats suggested "not much". The vast bulk of traffic on the old site came from search engines or clicking through on the site, not querying directly on the site. Even if I wanted to add search just because sites "should have it", a big input box on the page somewhere was honestly not exciting me design wise.
We'll see how it goes and I'll happily take feedback on this telling me I'm wrong. Of course if I am, I won't be adding in the feature via Ghost and I'll have to look at third party options instead, but let's see how it goes.
Open source
Not much to say here other than that everything you see here, namely the Ghost template, JS, CSS and Gulp bits are all in a public GitHub repo named troyhunt.com-ghost-theme. If you can fix or enhance or do anything else useful then by all means, submit a contribution and I'll be happy to take it if it helps the site.
Feedback
I'd love to hear it, particularly anything constructive around stuff that can be refined, clarified, fixed or otherwise made better. Of course I'd love to hear what you like as well; this has been a huge effort a long time coming and whilst I'm obviously very happy with the result, you're the people who have to look at it so your opinions matter enormously!
And that's it. First post on the new platform with many, many more to come yet.
![]()